GNU addr2line supports lookup by symbol name in addition to the existing
address lookup. llvm-symbolizer starting from
e144ae54dc supports lookup by symbol name.
This change extends this lookup with possibility to specify optional
offset.
Now the address for which source information is searched for can be
specified with offset:
llvm-symbolize --obj=abc.so "SYMBOL func_22+0x12"
It decreases the gap in features of llvm-symbolizer and GNU addr2line.
This lookup now is supported for code only.
Migrated from: https://reviews.llvm.org/D139859
Pull request: https://github.com/llvm/llvm-project/pull/75067
This is a follow up patch after .debug_names can now emit local type
unit entries when we compile with type units + DWARF5 + .debug_names.
The pull request that added this functionality was:
https://github.com/llvm/llvm-project/pull/70515
This patch makes sure that the DebugNamesDWARFIndex in LLDB will not
manually need to parse type units if they have a valid index. It also
fixes the index to be able to correctly extract name entries that
reference type unit DIEs. Added a test to verify things work as
expected.
llvm-gsymutil allows address ranges to overlap. There was a bug where if
we had debug info for a function with a range like [0x100-0x200) and a
symbol at the same start address yet with a larger range like
[0x100-0x300), we would randomly get either only information from the
first or second entry. This could cause lookups to fail due to the way
the binary search worked.
This patch makes sure that when lookups happen we find the first address
table entry that can match an address, and also ensures that we always
select the first FunctionInfo that could match. FunctionInfo entries are
sorted such that the most debug info rich entries come first. And if we
have two ranges that have the same start address, the smaller range
comes first and the larger one comes next. This patch also adds the
ability to iterate over all function infos with the same start address
to always find a range that contains the address.
Added a unit test to test this functionality that failed prior to this
fix and now succeeds.
Also fix an issue when dumping an entire GSYM file that has duplicate address entries where it used to always print out the binary search match for the FunctionInfo, not the actual data for the address index.
The DWARFUnitVector class lives inside of the DWARFContextState. Prior
to this fix a non const reference was being handed out to clients. When
fetching the DWO units, there used to be a "bool Lazy" parameter that
could be passed that would allow the DWARFUnitVector to parse individual
units on the fly. There were two major issues with this approach:
- not thread safe and causes crashes
- the accessor would check if DWARFUnitVector was empty and if not empty
it would return a partially filled in DWARFUnitVector if it was
constructed with "Lazy = true"
This patch fixes the issues by always fully parsing the DWARFUnitVector
when it is requested and only hands out a "const DWARFUnitVector &".
This allows the thread safety mechanism built into the DWARFContext
class to work corrrectly, and avoids the issue where if someone
construct DWARFUnitVector with "Lazy = true", and then calls an API that
partially fills in the DWARFUnitVector with individual entries, and then
someone accesses the DWARFUnitVector, they would get a partial and
incomplete listing of the DWARF units for the DWOs.
DWARF produced by LTO and BOLT can sometimes be broken where file
indexes are beyond the end of the line table's file list in the
prologue. This patch allows llvm-gsymutil to convert this DWARF without
crashing, and emits errors when:
line table contains entries with an invalid file index (line entry will
be removed) inline functions that have invalid DW_AT_call_file file
indexes when there are no line table entries for a function and we fall
back to making a single line table entry from the functions
DW_AT_decl_file/DW_AT_decl_line attributes, we make sure the
DW_AT_decl_file attribute is valid before emitting it.
Fix line table lookups in line tables with multiple lines with the same
address.
Compilers emit line tables that have multiple line table entries with
the same address. When doing lookups, we always need to use the last
line entry if a lookup address matches the address of one or more line
entries. This is because the size of an address range for a line uses
the next line entry to figure out how big the current line entry is. If
the next line entry has the same address, that means the current line
entry has a size of zero, so no bytes correspond to the line entry.
This patch ensures that lookups will always pick the last matching line
entry when the lookup address matches more than one line entry.
llvm/include/llvm/Support/VersionTuple.h doesn't need anything from
llvm/Support/Endian.h, but llvm/lib/DebugInfo/BTF/BTFParser.cpp relies
on a transitive inclusion of llvm/Support/Endian.h.
Recent versions of GNU binutils starting from 2.39 support symbol+offset
lookup in addition to the usual numeric address lookup. This change adds
symbol lookup to llvm-symbolize and llvm-addr2line.
Now llvm-symbolize behaves closer to GNU addr2line, - if the value specified
as address in command line or input stream is not a number, it is treated as
a symbol name. For example:
llvm-symbolize --obj=abc.so func_22
llvm-symbolize --obj=abc.so "CODE func_22"
This lookup is now supported only for functions. Specification with
offset is not supported yet.
This is a recommit of 2b27948783, reverted
in 39fec5457c because the test
llvm/test/Support/interrupts.test started failing on Windows. The test was
changed in 18f036d010 and is also updated in
this commit.
Differential Revision: https://reviews.llvm.org/D149759
C++20 comes with std::erase to erase a value from std::vector. This
patch renames llvm::erase_value to llvm::erase for consistency with
C++20.
We could make llvm::erase more similar to std::erase by having it
return the number of elements removed, but I'm not doing that for now
because nobody seems to care about that in our code base.
Since there are only 50 occurrences of erase_value in our code base,
this patch replaces all of them with llvm::erase and deprecates
llvm::erase_value.
These files satisfy all of the following:
- misc-include-cleaner indicates that these files do not need
Endian.h.
- They do not mention "endian" anywhere.
- They do not include any *.inc or *.def, which could need
llvm::support::endian.
In ef762e5e7292, I shifted around where errors were reported when
failing to parse and/or validate DWARFUnitHeaders. When we are doing so
in DWARFContext::fixupIndex, the actual error message isn't prefixed
with `warning:` like it would be elsewhere (because of the way
`logAllUnhandledErrors` is implemented).
Instead of reporting the error directly through the DWARFContext passed
in as an argument, it would be more flexible to have extract return the
error and allow the caller to react appropriately.
This will be useful for using llvm's DWARFHeaderUnit from lldb which may
report header extraction errors through a different mechanism.
Previous to this fix, if we had a DW_TAG_subprogram that had a
DW_AT_linkage_name that was empty, it would attempt to use this name
which would cause an error to be emitted when saving the gsym file to
disk:
error: DWARF conversion failed: : attempted to encode invalid
FunctionInfo object
This patch fixes this issue and adds a unit test case.
Note that llvm::support::endianness has been renamed to
llvm::endianness while becoming an enum class as opposed to an
enum. This patch replaces support::{big,little,native} with
llvm::endianness::{big,little,native}.
Note that llvm::support::endianness has been renamed to
llvm::endianness while becoming an enum class as opposed to an enum.
This patch replaces llvm::support::{big,little,native} with
llvm::endianness::{big,little,native}.
Now that llvm::support::endianness has been renamed to
llvm::endianness, we can use the shorter form. This patch replaces
support::endianness::{big,little,native} with
llvm::endianness::{big,little,native}.
Right now DWARFContext for DWO/DWP that is created is not thread safe.
Changed it so that thread safety is inherited from the main
binary DWARFContext.
For now, data location expression is hard coded to little endian. We are
going to support sanitizers on AIX which is big endian. Support big
endian too in the data location expression parser of llvm-symbolizer.
Now that llvm::support::endianness has been renamed to
llvm::endianness, we can use the shorter form. This patch replaces
llvm::support::endianness with llvm::endianness.
Now that llvm::support::endianness has been renamed to
llvm::endianness, we can directly get endianness from the llvm
namespace. We don't need to go through support.
Changed so that when Abbrev code is printed out for entry it is done in
the same
way as in Abbrev table.
Once letters are present in a hex number in abbrev table they will be
lower case,
and in the Entry upper case. Which makes FIleCheck Pattern recognition
fail.
Example in: llvm/test/tools/llvm-dwarfdump/X86/debug-names-misaligned.s
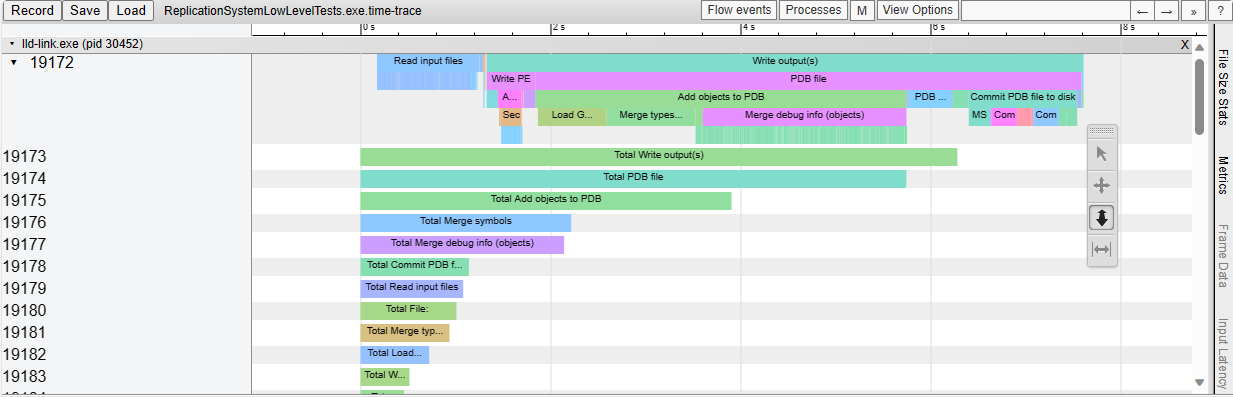
This adds support for generating Chrome-tracing .json profile traces in
the LLD COFF driver.
Also add the necessary time scopes, so that the profile trace shows in
great detail which tasks are executed.
As an example, this is what we see when linking a Unreal Engine
executable:
system_endianness() just returns llvm::endianness::native, a
compile-time constant equivalent to std::native in C++20. This patch
deprecates system_endianness() while replacing all invocations of
system_endianness() with llvm::endianness::native.
While we are at it, this patch replaces
llvm::support::endianness::{big,little} with
llvm::endianness::{big,little} in those statements that happen to call
system_endianness(). It does not go out of its way to replace other
occurrences of llvm::support::endianness::{big,little}.
Recent versions of GNU binutils starting from 2.39 support symbol+offset
lookup in addition to the usual numeric address lookup. This change adds
symbol lookup to llvm-symbolize and llvm-addr2line.
Now llvm-symbolize behaves closer to GNU addr2line, - if the value specified
as address in command line or input stream is not a number, it is treated as
a symbol name. For example:
llvm-symbolize --obj=abc.so func_22
llvm-symbolize --obj=abc.so "CODE func_22"
This lookup is now supported only for functions. Specification with
offset is not supported yet.
Differential Revision: https://reviews.llvm.org/D149759
Without this patch, we pass Endian as one of the parameters to the
constructor of DataExtractor. The problem is that Endian is of:
enum endianness {big, little, native};
whereas the constructor is expecting "bool IsLittleEndian". That is,
we are relying on an implicit conversion to convert big and little to
false and true, respectively.
When we migrate llvm::support::endianness to std::endian in future, we
can no longer rely on an implicit conversion because std::endian is
declared with "enum class". Even if we could, the conversion would
not be guaranteed to work because, for example, libcxx defines:
enum class endian {
little = 0xDEAD,
big = 0xFACE,
:
where big and little are not boolean values.
This patch fixes the problem by properly converting Endian to a
boolean value.
The `S_INLINEES` debug symbol is used to record all the functions that
are directly inlined within the current function (nested inlining is
ignored).
This change implements support for emitting the `S_INLINEES` debug
symbol in LLVM, and cleans up how the `S_INLINEES` and `S_CALLEES` debug
symbols are dumped.
To make DWARFDebugAbbrev more amenable to error-handling, I would like
to change the return type of DWARFDebugAbbrev::parse from `void` to
`Error`. Users of DWARFDebugAbbrev can consume the error if they want to
use all the valid DWARF that was parsed (without worrying about the
malformed DWARF) or stop when the parse fails if the use case needs to
be strict.
This also will bring the LLVM DWARFDebugAbbrev interface closer to
LLDB's which opens up the opportunity for LLDB adopt the LLVM
implementation with minimal changes.
Extend llvm-objdump to show CO-RE relocations when `-r` option is
passed and object file has .BTF and .BTF.ext sections.
For example, the following C program:
#define __pai __attribute__((preserve_access_index))
struct foo { int i; int j;} __pai;
struct bar { struct foo f[7]; } __pai;
extern void sink(void *);
void root(struct bar *bar) {
sink(&bar[2].f[3].j);
}
Should lead to the following objdump output:
$ clang --target=bpf -O2 -g t.c -c -o - | \
llvm-objdump --no-addresses --no-show-raw-insn -dr -
...
r2 = 0x94
CO-RE <byte_off> [2] struct bar::[2].f[3].j (2:0:3:1)
r1 += r2
call -0x1
R_BPF_64_32 sink
exit
...
More examples could be found in unit tests, see BTFParserTest.cpp.
To achieve this:
- Move CO-RE relocation kinds definitions from BPFCORE.h to BTF.h.
- Extend BTF.h with types derived from BTF::CommonType, e.g.
BTF::IntType and BTF::StrutType, to allow dyn_cast() and access to
type additional data.
- Extend BTFParser to load BTF type and relocation data.
- Modify llvm-objdump.cpp to create instance of BTFParser when
disassembly of object file with BTF sections is processed and `-r`
flag is supplied.
Additional information about CO-RE is available at [1].
[1] https://docs.kernel.org/bpf/llvm_reloc.html
Depends on D149058
Differential Revision: https://reviews.llvm.org/D150079
ObjectiveC has its own extra accelerator table entries that are helpful for the
debugger. This patch relaxes the DWARFVerifier so that it accepts those in DWARF
5's debug_names.
Differential Revision: https://reviews.llvm.org/D159471
The DWARFLinker library has code to identify ObjC selector names, which is used
by the debug linker to generate accelerator table entries. In the future, we
would like the DWARF verifier to also have access to such code, so that it can
identify these names when verifying accelerator tables (e.g. debug_names).
This patch follows the same intent of D155723, where we also moved code
generating simplified template names.
Since this is moving code around and changing the log, we also replace raw
pointer manipulation with the more expressive
StringRef::{drop_front,take_front,...} methods.
We also change a test so that it verifies its output, and that requires having
dsymutil not write to stdout.
Differential Revision: https://reviews.llvm.org/D158980