This allows the input section matching algorithm to be separated from
output section descriptions. This allows a group of sections to be
assigned to multiple output sections, providing an explicit version of
--enable-non-contiguous-regions's spilling that doesn't require altering
global linker script matching behavior with a flag. It also makes the
linker script language more expressive even if spilling is not intended,
since input section matching can be done in a different order than
sections are placed in an output section.
The implementation reuses the backend mechanism provided by
--enable-non-contiguous-regions, so it has roughly similar semantics and
limitations. In particular, sections cannot be spilled into or out of
INSERT, OVERWRITE_SECTIONS, or /DISCARD/. The former two aren't
intrinsic, so it may be possible to relax those restrictions later.
GNU ld since 2.41 supports this option, which is mildly useful. It omits
the section header table and non-ALLOC sections (including
.symtab/.strtab (--strip-all)).
This option is simple to implement and might be used by LLDB to test
program headers parsing without the section header table (#100900).
-z sectionheader, which is the default, is also added.
Pull Request: https://github.com/llvm/llvm-project/pull/101286
This reverts commit f55b79f59a.
The known issues with chained fixups have been addressed by #98913,
#98305, #97156 and #95171.
Compared to the original commit, support for xrOS (which postdates
chained fixups' introduction) was added and an unnecessary test change
was removed.
----------
Original commit message:
Enable chained fixups in lld when all platform and version criteria are
met. This is an attempt at simplifying the logic used in ld 907:
93d74eafc3/src/ld/Options.cpp (L5458-L5549)
Some changes were made to simplify the logic:
- only enable chained fixups for macOS from 13.0 to avoid the arch check
- only enable chained fixups for iphonesimulator from 16.0 to avoid the
arch check
- don't enable chained fixups for not specifically listed platforms
- don't enable chained fixups for arm64_32
Implement the two commands described by
https://sourceware.org/binutils/docs/ld/Miscellaneous-Commands.html
After `outputSections` is available, check each output section described
by at least one `NOCROSSREFS`/`NOCROSSERFS_TO` command. For each checked
output section, scan relocations from its input sections.
This step is slow, therefore utilize `parallelForEach(isd->sections, ...)`.
To support non SHF_ALLOC sections, `InputSectionBase::relocations`
(empty) cannot be used. In addition, we may explore eliminating this
member to speed up relocation scanning.
Some parse code is adapted from #95714.
Close#41825
Pull Request: https://github.com/llvm/llvm-project/pull/98773
This patch improves GNU ld compatibility.
Close#87891: Support `OUTPUT_FORMAT(binary)`, which is like
--oformat=binary. --oformat=binary takes precedence over an ELF
`OUTPUT_FORMAT`.
In addition, if more than one OUTPUT_FORMAT command is specified, only
check the first one.
Pull Request: https://github.com/llvm/llvm-project/pull/98837
The current default, build-id=fast, is only 8 bytes due to the usage of
64-bit XXH3. This is incompatible with RPM packaging tools which
requires >=16 bytes [1].
In Clang the ENABLE_LINKER_BUILD_ID define makes it pass --build-id
without a specific hash type. When also defaulting to LLD, this provides
a pretty broken default out-of-box.
Using XXH3 was a considerable performance advantage when build-id was
first implemented, because sha1 was really sha1 and rather slow.
Nowadays sha1 is just 160-bit BLAKE3 which is decently fast and not
cryptographically broken, so it should be a good default.
Note that the default remains "fast" for wasm because sha1 for wasm is
still real sha1.
Close https://github.com/llvm/llvm-project/issues/43483.
[1]:
b7d427728b/build/files.c (L1883)
GNU ld's relocatable linking behaviors:
* Sections with the `SHF_GROUP` flag are handled like sections matched
by the `--unique=pattern` option. They are processed like orphan
sections and ignored by input section descriptions.
* Section groups' (usually named `.group`) content is updated as the
section indexes are updated. Section groups can be discarded with
`/DISCARD/ : { *(.group) }`.
`-r --force-group-allocation` discards section groups and allows
sections with the `SHF_GROUP` flag to be matched like normal sections.
If two section group members are placed into the same output section,
their relocation sections (if present) are combined as well.
This behavior can be useful when -r output is used as a pseudo shared
object (e.g., FreeBSD's amd64 kernel modules, CHERIoT compartments).
This patch implements --force-group-allocation:
* Input SHT_GROUP sections are discarded.
* Input sections do not get the SHF_GROUP flag, so `addInputSec`
will combine relocation sections if their relocated section group
members are combined.
The default behavior is:
* Input SHT_GROUP sections are retained.
* Input SHF_GROUP sections can be matched (unlike GNU ld)
* Input SHF_GROUP sections keep the SHF_GROUP flag, so `addInputSec`
will create different OutputDesc copies.
GNU ld provides the `FORCE_GROUP_ALLOCATION` command, which is not
implemented.
Pull Request: https://github.com/llvm/llvm-project/pull/94704
When enabled, input sections that would otherwise overflow a memory
region are instead spilled to the next matching output section.
This feature parallels the one in GNU LD, but there are some differences
from its documented behavior:
- /DISCARD/ only matches previously-unmatched sections (i.e., the flag
does not affect it).
- If a section fails to fit at any of its matches, the link fails
instead of discarding the section.
- The flag --enable-non-contiguous-regions-warnings is not implemented,
as it exists to warn about such occurrences.
The implementation places stubs at possible spill locations, and
replaces them with the original input section when effecting spills.
Spilling decisions occur after address assignment. Sections are spilled
in reverse order of assignment, with each spill naively decreasing the
size of the affected memory regions. This continues until the memory
regions are brought back under size. Spilling anything causes another
pass of address assignment, and this continues to fixed point.
Spilling after rather than during assignment allows the algorithm to
consider the size effects of unspillable input sections that appear
later in the assignment. Otherwise, such sections (e.g. thunks) may
force an overflow, even if spilling something earlier could have avoided
it.
A few notable feature interactions occur:
- Stubs affect alignment, ONLY_IF_RO, etc, broadly as if a copy of the
input section were actually placed there.
- SHF_MERGE synthetic sections use the spill list of their first
contained input section (the one that gives the section its name).
- ICF occurs oblivious to spill sections; spill lists for merged-away
sections become inert and are removed after assignment.
- SHF_LINK_ORDER and .ARM.exidx are ordered according to the final
section ordering, after all spilling has completed.
- INSERT BEFORE/AFTER and OVERWRITE_SECTIONS are explicitly disallowed.
When enabled, input sections that would otherwise overflow a memory
region are instead spilled to the next matching output section.
This feature parallels the one in GNU LD, but there are some differences
from its documented behavior:
- /DISCARD/ only matches previously-unmatched sections (i.e., the flag
does not affect it).
- If a section fails to fit at any of its matches, the link fails
instead of discarding the section.
- The flag --enable-non-contiguous-regions-warnings is not implemented,
as it exists to warn about such occurrences.
The implementation places stubs at possible spill locations, and
replaces them with the original input section when effecting spills.
Spilling decisions occur after address assignment. Sections are spilled
in reverse order of assignment, with each spill naively decreasing the
size of the affected memory regions. This continues until the memory
regions are brought back under size. Spilling anything causes another
pass of address assignment, and this continues to fixed point.
Spilling after rather than during assignment allows the algorithm to
consider the size effects of unspillable input sections that appear
later in the assignment. Otherwise, such sections (e.g. thunks) may
force an overflow, even if spilling something earlier could have avoided
it.
A few notable feature interactions occur:
- Stubs affect alignment, ONLY_IF_RO, etc, broadly as if a copy of the
input section were actually placed there.
- SHF_MERGE synthetic sections use the spill list of their first
contained input section (the one that gives the section its name).
- ICF occurs oblivious to spill sections; spill lists for merged-away
sections become inert and are removed after assignment.
- SHF_LINK_ORDER and .ARM.exidx are ordered according to the final
section ordering, after all spilling has completed.
- INSERT BEFORE/AFTER and OVERWRITE_SECTIONS are explicitly disallowed.
zstd excels at scaling from low-ratio-very-fast to
high-ratio-pretty-slow. Some users prioritize speed and prefer disk read
speed, while others focus on achieving the highest compression ratio
possible, similar to traditional high-ratio codecs like LZMA.
Add an optional `level` to `--compress-sections` (#84855) to cater to
these diverse needs. While we initially aimed for a one-size-fits-all
approach, this no longer seems to work.
(https://richg42.blogspot.com/2015/11/the-lossless-decompression-pareto.html)
When --compress-debug-sections is used together, make
--compress-sections take precedence since --compress-sections is usually
more specific.
Remove the level distinction between -O/-O1 and -O2 for
--compress-debug-sections=zlib for a more consistent user experience.
Pull Request: https://github.com/llvm/llvm-project/pull/90567
`clang -g -gpubnames` (with optional -gsplit-dwarf) creates the
`.debug_names` section ("per-CU" index). By default lld concatenates
input `.debug_names` sections into an output `.debug_names` section.
LLDB can consume the concatenated section but the lookup performance is
not good.
This patch adds --debug-names to create a per-module index by combining
the per-CU indexes into a single index that covers the entire load
module. The produced `.debug_names` is a replacement for `.gdb_index`.
Type units (-fdebug-types-section) are not handled yet.
Co-authored-by: Fangrui Song <i@maskray.me>
---------
Co-authored-by: Fangrui Song <i@maskray.me>
--compress-sections <section-glib>=[none|zlib|zstd] is similar to
--compress-debug-sections but applies to broader sections without the
SHF_ALLOC flag. lld will report an error if a SHF_ALLOC section is
matched. An interesting use case is to compress `.strtab`/`.symtab`,
which consume a significant portion of the file size (15.1% for a
release build of Clang).
An older revision is available at https://reviews.llvm.org/D154641 .
This patch focuses on non-allocated sections for safety. Moving
`maybeCompress` as D154641 does not handle STT_SECTION symbols for
`-r --compress-debug-sections=zlib` (see `relocatable-section-symbol.s`
from #66804).
Since different output sections may use different compression
algorithms, we need CompressedData::type to generalize
config->compressDebugSections.
GNU ld feature request: https://sourceware.org/bugzilla/show_bug.cgi?id=27452
Link: https://discourse.llvm.org/t/rfc-compress-arbitrary-sections-with-ld-lld-compress-sections/71674
Pull Request: https://github.com/llvm/llvm-project/pull/84855
The ELF linker transitioned away from archive indexes in
https://reviews.llvm.org/D117284.
This paves the way for supporting `--start-lib`/`--end-lib` (See #77960)
The ELF linker unified library handling with `--start-lib`/`--end-lib` and removed
the ArchiveFile class in https://reviews.llvm.org/D119074.
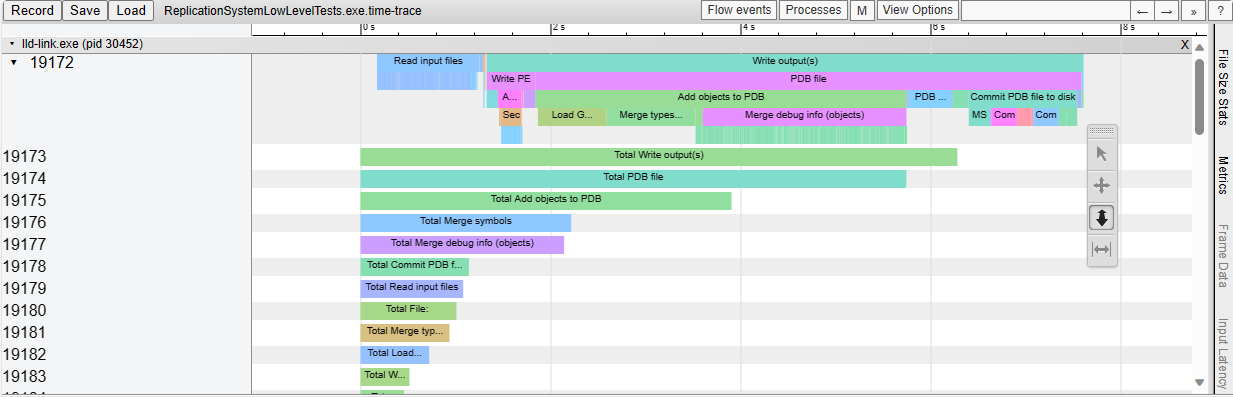
This adds support for generating Chrome-tracing .json profile traces in
the LLD COFF driver.
Also add the necessary time scopes, so that the profile trace shows in
great detail which tasks are executed.
As an example, this is what we see when linking a Unreal Engine
executable:
Close#57618: currently we align the end of PT_GNU_RELRO to a
common-page-size
boundary, but do not align the end of the associated PT_LOAD. This is
benign
when runtime_page_size >= common-page-size.
However, when runtime_page_size < common-page-size, it is possible that
`alignUp(end(PT_LOAD), page_size) < alignDown(end(PT_GNU_RELRO),
page_size)`.
In this case, rtld's mprotect call for PT_GNU_RELRO will apply to
unmapped
regions and lead to an error, e.g.
```
error while loading shared libraries: cannot apply additional memory protection after relocation: Cannot allocate memory
```
To fix the issue, add a padding section .relro_padding like mold, which
is contained in the PT_GNU_RELRO segment and the associated PT_LOAD
segment. The section also prevents strip from corrupting PT_LOAD program
headers.
.relro_padding has the largest `sortRank` among RELRO sections.
Therefore, it is naturally placed at the end of `PT_GNU_RELRO` segment
in the absence of `PHDRS`/`SECTIONS` commands.
In the presence of `SECTIONS` commands, we place .relro_padding
immediately before a symbol assignment using DATA_SEGMENT_RELRO_END (see
also https://reviews.llvm.org/D124656), if present.
DATA_SEGMENT_RELRO_END is changed to align to max-page-size instead of
common-page-size.
Some edge cases worth mentioning:
* ppc64-toc-addis-nop.s: when PHDRS is present, do not append
.relro_padding
* avoid-empty-program-headers.s: when the only RELRO section is .tbss,
it is not part of PT_LOAD segment, therefore we do not append
.relro_padding.
---
Close#65002: GNU ld from 2.39 onwards aligns the end of PT_GNU_RELRO to
a
max-page-size boundary (https://sourceware.org/PR28824) so that the last
page is
protected even if runtime_page_size > common-page-size.
In my opinion, losing protection for the last page when the runtime page
size is
larger than common-page-size is not really an issue. Double mapping a
page of up
to max-common-page for the protection could cause undesired VM waste.
Internally
we had users complaining about 2MiB max-page-size applying to shared
objects.
Therefore, the end of .relro_padding is padded to a common-page-size
boundary. Users who are really anxious can set common-page-size to match
their runtime page size.
---
17 tests need updating as there are lots of change detectors.
This patch adds support to lld for --fat-lto-objects. We add a new
--fat-lto-objects option to LLD, and slightly change how it chooses input
files in the driver when the option is set.
Fat LTO objects contain both LTO compatible IR, as well as generated object
code. This allows users to defer the choice of whether to use LTO or not to
link-time. This is a feature available in GCC for some time, and makes the
existing -ffat-lto-objects option functional in the same way as GCC's.
If the --fat-lto-objects option is passed to LLD and the input files are fat
object files, then the linker will chose the LTO compatible bitcode sections
embedded within the fat object and link them together using LTO. Otherwise,
standard object file linking is done using the assembly section in the object
files.
The previous version of this patch had a missing `REQUIRES: x86` line in
`fatlto.invalid.s`. Additionally, it was reported that this patch caused
a test failure in `export-dynamic-symbols.s`, however,
29112a9946 disabled the
`export-dynamic-symbols.s` test on Windows due to a quotation difference
between platforms, unrelated to this patch.
Original RFC: https://discourse.llvm.org/t/rfc-ffat-lto-objects-support/63977
Reviewed By: MaskRay
Differential Revision: https://reviews.llvm.org/D146778
This adds support for the LoongArch ELF psABI v2.00 [1] relocation
model to LLD. The deprecated stack-machine-based psABI v1 relocs are not
supported.
The code is tested by successfully bootstrapping a Gentoo/LoongArch
stage3, complete with common GNU userland tools and both the LLVM and
GNU toolchains (GNU toolchain is present only for building glibc,
LLVM+Clang+LLD are used for the rest). Large programs like QEMU are
tested to work as well.
[1]: https://loongson.github.io/LoongArch-Documentation/LoongArch-ELF-ABI-EN.html
Reviewed By: MaskRay, SixWeining
Differential Revision: https://reviews.llvm.org/D138135
This reverts commit c9953d9891 and a
forward fix in 3a45b843de.
D14677 causes some failure on windows bots that the forward fix did not
address. Thus I'm reverting until the underlying cause can me triaged.
This patch adds support to lld for --fat-lto-objects. We add a new
--fat-lto-objects flag to LLD, and slightly change how it chooses input
files in the driver when the flag is set.
Fat LTO objects contain both LTO compatible IR, as well as generated object
code. This allows users to defer the choice of whether to use LTO or not to
link-time. This is a feature available in GCC for some time, and makes the
existing -ffat-lto-objects flag functional in the same way as GCC's.
If the --fat-lto-objects option is passed to LLD and the input files are fat
object files, then the linker will chose the LTO compatible bitcode sections
embedded within the fat object and link them together using LTO. Otherwise,
standard object file linking is done using the assembly section in the object
files.
Original RFC: https://discourse.llvm.org/t/rfc-ffat-lto-objects-support/63977
Depends on D146777
Reviewed By: MaskRay
Differential Revision: https://reviews.llvm.org/D146778
We want lld-link to automatically find compiler-rt's and
libc++ when it's in the same directory as the rest of the
toolchain. This is because on Windows linking isn't done
via the clang driver - but instead invoked directly.
This prepends: <llvm>/lib <llvm>/lib/clang/XX/lib and
<llvm>/lib/clang/XX/lib/windows automatically to the library
search paths.
Related to #63827
Differential Revision: https://reviews.llvm.org/D151188
This patch is spun out of https://reviews.llvm.org/D151188
and makes it possible for lld-link to find libraries with
relative paths. This will be used later to implement the
changes to autolinking runtimes explained in #63827
Differential Revision: https://reviews.llvm.org/D155268
--remap-inputs-file= can be specified multiple times, each naming a
remap file that contains `from-glob=to-file` lines or `#`-led comments.
('=' is used a separator a la -fdebug-prefix-map=)
--remap-inputs-file= can be used to:
* replace an input file. E.g. `"*/libz.so=exp/libz.so"` can replace a resolved
`-lz` without updating the input file list or (if used) a response file.
When debugging an application where a bug is isolated to one single
input file, this option gives a convenient way to test fixes.
* remove an input file with `/dev/null` (changed to `NUL` on Windows), e.g.
`"a.o=/dev/null"`. A build system may add unneeded dependencies.
This option gives a convenient way to test the result removing some inputs.
`--remap-inputs=a.o=aa.o` can be specified to provide one pattern without using
an extra file.
(bash/zsh process substitution is handy for specifying a pattern without using
a remap file, e.g. `--remap-inputs-file=<(printf 'a.o=aa.o')`, but it may be
unavailable in some systems. An extra file can be inconvenient for a build
system.)
Exact patterns are tested before wildcard patterns. In case of a tie, the first
patterns wins. This is an implementation detail that users should not rely on.
Co-authored-by: Marco Elver <elver@google.com>
Link: https://discourse.llvm.org/t/rfc-support-exclude-inputs/70070
Reviewed By: melver, peter.smith
Differential Revision: https://reviews.llvm.org/D148859
Embedded systems that do not use an ELF loader locate the
.ARM.exidx exception table via linker defined __exidx_start and
__exidx_end rather than use the PT_ARM_EXIDX program header. This
means that some linker scripts such as the picolibc C library's
linker script, do not have the .ARM.exidx sections at offset 0 in
the OutputSection. For example:
.except_unordered : {
. = ALIGN(8);
PROVIDE(__exidx_start = .);
*(.ARM.exidx*)
PROVIDE(__exidx_end = .);
} >flash AT>flash :text
This is within the specification of Arm exception tables, and is
handled correctly by ld.bfd.
This patch has 2 parts. The first updates the writing of the data
of the .ARM.exidx SyntheticSection to account for a non-zero
OutputSection offset. The second part makes the PT_ARM_EXIDX program
header generation a special case so that it covers only the
SyntheticSection and not the parent OutputSection. While not strictly
necessary for programs locating the exception tables via the symbols
it may cause ELF utilities that locate the exception tables via
the PT_ARM_EXIDX program header to fail. This does not seem to be the
case for GNU and LLVM readelf which seems to look for the
SHT_ARM_EXIDX section.
Differential Revision: https://reviews.llvm.org/D148033
Currently we take the first SHT_RISCV_ATTRIBUTES (.riscv.attributes) as the
output. If we link an object without an extension with an object with the
extension, the output Tag_RISCV_arch may not contain the extension and some
tools like objdump -d will not decode the related instructions.
This patch implements
Tag_RISCV_stack_align/Tag_RISCV_arch/Tag_RISCV_unaligned_access merge as
specified by
https://github.com/riscv-non-isa/riscv-elf-psabi-doc/blob/master/riscv-elf.adoc#attributes
For the deprecated Tag_RISCV_priv_spec{,_minor,_revision}, dump the attribute to
the output iff all input agree on the value. This is different from GNU ld but
our simple approach should be ok for deprecated tags.
`RISCVAttributeParser::handler` currently warns about unknown tags. This
behavior is retained. In GNU ld arm, tags >= 64 (mod 128) are ignored with a
warning. If RISC-V ever wants to do something similar
(https://github.com/riscv-non-isa/riscv-elf-psabi-doc/issues/352), consider
documenting it in the psABI and changing RISCVAttributeParser.
Like GNU ld, zero value integer attributes and empty string attributes are not
dumped to the output.
Reviewed By: asb, kito-cheng
Differential Revision: https://reviews.llvm.org/D138550
Allowing incorrect version scripts is not a helpful default. Flip that
to help users find their bugs at build time rather than at run time.
Reviewed By: MaskRay
Differential Revision: https://reviews.llvm.org/D135402
https://github.com/riscv/riscv-elf-psabi-doc/pull/190 introduced STO_RISCV_VARIANT_CC.
The linker should:
* Copy the STO_RISCV_VARIANT_CC bit to .symtab/.dynsym: already fulfilled after
82ed93ea05
* Produce DT_RISCV_VARIANT_CC if at least one R_RISCV_JUMP_SLOT relocation
references a symbol with the STO_RISCV_VARIANT_CC bit. Done by this patch.
Reviewed By: kito-cheng
Differential Revision: https://reviews.llvm.org/D107951
Solve two issues that showed up when using LLD with Unreal Engine & FASTBuild:
1. It seems the S_OBJNAME record doesn't always record the "precomp signature". We were relying on that to match the PCH.OBJ with their dependent-OBJ.
2. MSVC link.exe is able to link a PCH.OBJ when the "precomp signatureÈ doesn't match, but LLD was failing. This was occuring since the Unreal Engine Build Tool was compiling the PCH.OBJ, but the dependent-OBJ were compiled & cached through FASTBuild. Upon a clean rebuild, the PCH.OBJs were recompiled by the Unreal Build Tool, thus the "precomp signatures" were changing; however the OBJs were already cached by FASTBuild, thus having an old "precomp signatures".
We now ignore "precomp signatures" and properly fallback to cmd-line name lookup, like MSVC link.exe does, and only fail if the PCH.OBJ type stream doesn't match the count expected by the dependent-OBJ.
Differential Revision: https://reviews.llvm.org/D136762
Previously, we used SHA-1 for hashing the CodeView type records.
SHA-1 in `GloballyHashedType::hashType()` is coming top in the profiles. By simply replacing with BLAKE3, the link time is reduced in our case from 15 sec to 13 sec. I am only using MSVC .OBJs in this case. As a reference, the resulting .PDB is approx 2.1GiB and .EXE is approx 250MiB.
Differential Revision: https://reviews.llvm.org/D137101
MSVC records the command line arguments in S_ENVBLOCK, skipping the input file arguments.
This patch adds this filtering on lld-link side.
Differential Revision: https://reviews.llvm.org/D137723
Allowing incorrect version scripts is not a helpful default. Flip that
to help users find their bugs at build time rather than at run time.
Reviewed By: MaskRay
Differential Revision: https://reviews.llvm.org/D135402
Mach-O ld64 supports -w to suppress warnings. GNU ld 2.40 will support the
option as well (https://sourceware.org/bugzilla/show_bug.cgi?id=29654).
This feature has some small value. E.g. when analyzing a large executable with
relocation overflow issues, we may use --noinhibit-exec --emit-relocs to get an
output file with static relocations despite relocation overflow issues. -w can
significantly improve the link time as printing the massive warnings is slow.
Reviewed By: peter.smith
Differential Revision: https://reviews.llvm.org/D136569
This reverts commit 096f93e73d.
Revert "[Libomptarget] Make the plugins ingore undefined exported symbols"
This reverts commit 3f62314c23.
Revert "[LLD] Enable --no-undefined-version by default."
This reverts commit 7ec8b0d162.
Three commits are reverted because of the current omp build fail
with GNU ld. See discussion here: https://reviews.llvm.org/rG096f93e73dc3
Allowing incorrect version scripts is not a helpful default. Flip that
to help users find their bugs at build time rather than at run time.
Reviewed By: MaskRay
Differential Revision: https://reviews.llvm.org/D135402
`clang -gz=zstd a.o` passes this option to the linker. This option compresses output
debug sections with zstd and sets ch_type to ELFCOMPRESS_ZSTD. As of today, very
few DWARF consumers recognize ELFCOMPRESS_ZSTD.
Use the llvm::zstd::compress API with level llvm::zstd::DefaultCompression (5),
which we may tune after we have more experience with zstd output.
zstd has built-in parallel compression support (so we don't need to do D117853
for zlib), which is not leveraged yet.
Reviewed By: peter.smith
Differential Revision: https://reviews.llvm.org/D133548
so that lld accepts relocatable object files produced by `clang -c -g -gz=zstd`.
We don't want to increase the size of InputSection, so do redundant but cheap
ch_type checks instead.
Differential Revision: https://reviews.llvm.org/D129406