I'm planning to remove StringRef::equals in favor of
StringRef::operator==.
- StringRef::operator==/!= outnumber StringRef::equals by a factor of
276 under llvm-project/ in terms of their usage.
- The elimination of StringRef::equals brings StringRef closer to
std::string_view, which has operator== but not equals.
- S == "foo" is more readable than S.equals("foo"), especially for
!Long.Expression.equals("str") vs Long.Expression != "str".
Note that llvm::support::endianness has been renamed to
llvm::endianness while becoming an enum class as opposed to an
enum. This patch replaces support::{big,little,native} with
llvm::endianness::{big,little,native}.
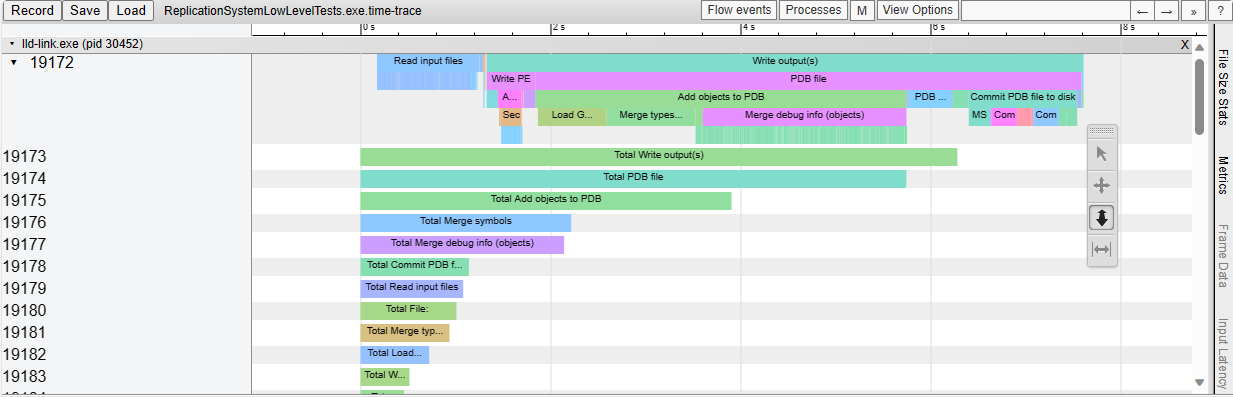
This adds support for generating Chrome-tracing .json profile traces in
the LLD COFF driver.
Also add the necessary time scopes, so that the profile trace shows in
great detail which tasks are executed.
As an example, this is what we see when linking a Unreal Engine
executable:
In preparation for removing the `#include "llvm/ADT/StringExtras.h"`
from the header to source file of `llvm/Support/Error.h`, first add in
all the missing includes that were previously included transitively
through this header.
Similar to how `makeArrayRef` is deprecated in favor of deduction guides, do the
same for `makeMutableArrayRef`.
Once all of the places in-tree are using the deduction guides for
`MutableArrayRef`, we can mark `makeMutableArrayRef` as deprecated.
Differential Revision: https://reviews.llvm.org/D141814
This reverts commit 7370ff624d.
(and 47fb8ae2f9).
This commit broke the symbol type in import libraries generated
for mingw autoexported symbols, when the source files were built
with LTO. I'll commit a testcase that showcases this issue after
the revert.
This patch relaxes the constraints on the error message saved in PDBInputFile when failing to load a pdb file.
Storing an `Error` member infers that it must be accessed exactly once, which doesn't fit in several scenarios:
- If an invalid PDB file is provided as input file but never used, a loading error is created but never handled, causing an assert at shutdown.
- PDB file created using MSVC's `/Zi` option : The loading error message must be displayed once per obj file.
Also, the state of `PDBInputFile` was altered when reading (taking) the `Error` member, causing issues:
- accessing it (taking the `Error`) makes the object look valid whereas it's not properly initialized
- read vs write concurrency on a same `PDBInputFile` in the ghash parallel algorithm
The solution adopted here was to instead store an optional error string, and generate Error objects from it on demand.
Differential Revision: https://reviews.llvm.org/D140333
This patch mechanically replaces None with std::nullopt where the
compiler would warn if None were deprecated. The intent is to reduce
the amount of manual work required in migrating from Optional to
std::optional.
This is part of an effort to migrate from llvm::Optional to
std::optional:
https://discourse.llvm.org/t/deprecating-llvm-optional-x-hasvalue-getvalue-getvalueor/63716
Solve two issues that showed up when using LLD with Unreal Engine & FASTBuild:
1. It seems the S_OBJNAME record doesn't always record the "precomp signature". We were relying on that to match the PCH.OBJ with their dependent-OBJ.
2. MSVC link.exe is able to link a PCH.OBJ when the "precomp signatureÈ doesn't match, but LLD was failing. This was occuring since the Unreal Engine Build Tool was compiling the PCH.OBJ, but the dependent-OBJ were compiled & cached through FASTBuild. Upon a clean rebuild, the PCH.OBJs were recompiled by the Unreal Build Tool, thus the "precomp signatures" were changing; however the OBJs were already cached by FASTBuild, thus having an old "precomp signatures".
We now ignore "precomp signatures" and properly fallback to cmd-line name lookup, like MSVC link.exe does, and only fail if the PCH.OBJ type stream doesn't match the count expected by the dependent-OBJ.
Differential Revision: https://reviews.llvm.org/D136762
Previously, we used SHA-1 for hashing the CodeView type records.
SHA-1 in `GloballyHashedType::hashType()` is coming top in the profiles. By simply replacing with BLAKE3, the link time is reduced in our case from 15 sec to 13 sec. I am only using MSVC .OBJs in this case. As a reference, the resulting .PDB is approx 2.1GiB and .EXE is approx 250MiB.
Differential Revision: https://reviews.llvm.org/D137101
Patch created by running:
rg -l parallelForEachN | xargs sed -i '' -c 's/parallelForEachN/parallelFor/'
No behavior change.
Differential Revision: https://reviews.llvm.org/D128140
Otherwise, with recent versions of libstdc++, clang can't tell that the
atomic operations are properly aligned, and generates calls to
libatomic. (Actually, because of the use of reinterpret_cast, it wasn't
guaranteed to be aligned, but I think it ended up being aligned in
practice.)
Fixes https://github.com/llvm/llvm-project/issues/54790 , the part where
LLVM failed to build.
Differential Revision: https://reviews.llvm.org/D123872
Follow-up from 98bc304e9f - while that
commit fixed when you had two PDBs colliding on the same Guid it didn't
fix the case where you had more than two PDBs using the same Guid.
This commit fixes that and also tests much more carefully that all
the types are correct no matter the order.
Reviewed By: aganea, saudi
Differential Revision: https://reviews.llvm.org/D123185
Microsoft shipped a bunch of PDB files with broken/invalid GUIDs
which lead lld to use 0xFF as the key for these files in an internal
cache. When multiple files have this key it will lead to collisions
and confused symbol lookup.
Several approaches to fix this was considered. Including making the key
the path to the PDB file, but this requires some filesystem operations
in order to normalize the file path.
Since this only happens with malformatted PDB files and we haven't
seen this before they malformatted files where shipped with visual
studio we probably shouldn't optimize for this use-case.
Instead we now just don't insert files with Guid == 0xFF into the
cache map and warn if we get collisions so similar problems can be
found in the future instead of being silent.
Discussion about the root issue and the approach to this fix can be found on Github: https://github.com/llvm/llvm-project/issues/54487
Reviewed By: aganea
Differential Revision: https://reviews.llvm.org/D122372
Original commit description:
[LLD] Remove global state in lld/COFF
This patch removes globals from the lldCOFF library, by moving globals
into a context class (COFFLinkingContext) and passing it around wherever
it's needed.
See https://lists.llvm.org/pipermail/llvm-dev/2021-June/151184.html for
context about removing globals from LLD.
I also haven't moved the `driver` or `config` variables yet.
Differential Revision: https://reviews.llvm.org/D109634
This reverts commit a2fd05ada9.
Original commits were b4fa71eed3
and e03c7e367a.
This patch removes globals from the lldCOFF library, by moving globals
into a context class (COFFLinkingContext) and passing it around wherever
it's needed.
See https://lists.llvm.org/pipermail/llvm-dev/2021-June/151184.html for
context about removing globals from LLD.
I also haven't moved the `driver` or `config` variables yet.
Differential Revision: https://reviews.llvm.org/D109634
Before this patch, the maximum size of the GHASH table was 2^31 buckets. However we were storing the bucket index into a TypeIndex which has an input limit of (2^31)-4095 indices, see this link. Any value above that limit will improperly set the TypeIndex's high bit, which is interpreted as DecoratedItemIdMask. This used to cause bad indices on extraction when calling TypeIndex::toArrayIndex().
Differential Revision: https://reviews.llvm.org/D103297
Previously we simply didn't check this. Prereq to make the test suite
pass with ghash enabled by default.
Differential Revision: https://reviews.llvm.org/D102885
Before this patch, when using LLD with /DEBUG:GHASH and MSVC precomp.OBJ files, we had a bunch of:
lld-link: warning: S_[GL]PROC32ID record in blabla.obj refers to PDB item index 0x206ED1 which is not a LF[M]FUNC_ID record
This was caused by LF_FUNC_ID and LF_MFUNC_ID which didn't have correct mapping to the corresponding TPI records. The root issue was that the indexMapStorage was improperly re-assembled in UsePrecompSource::remapTpiWithGHashes.
After this patch, /DEBUG and /DEBUG:GHASH produce exactly the same debug infos in the PDB.
Differential Revision: https://reviews.llvm.org/D93732
This adds the following two new lines to /summary:
21351 Input OBJ files (expanded from all cmd-line inputs)
61 PDB type server dependencies
38 Precomp OBJ dependencies
1420669231 Input type records <<<<
78665073382 Input type records bytes <<<<
8801393 Merged TPI records
3177158 Merged IPI records
59194 Output PDB strings
71576766 Global symbol records
25416935 Module symbol records
2103431 Public symbol records
Differential Revision: https://reviews.llvm.org/D88703
Before this patch /summary was crashing with some .PCH.OBJ files, because tpiMap[srcIdx++] was reading at the wrong location. When the TpiSource depends on a .PCH.OBJ file, the types should be offset by the previously merged PCH.OBJ set of indices.
Differential Revision: https://reviews.llvm.org/D88678
Stored Error objects have to be checked, even if they are success
values.
This reverts commit 8d250ac3cd.
Relands commit 49b3459930655d879b2dc190ff8fe11c38a8be5f..
Original commit message:
-----------------------------------------
This makes type merging much faster (-24% on chrome.dll) when multiple
threads are available, but it slightly increases the time to link (+10%)
when /threads:1 is passed. With only one more thread, the new type
merging is faster (-11%). The output PDB should be identical to what it
was before this change.
To give an idea, here is the /time output placed side by side:
BEFORE | AFTER
Input File Reading: 956 ms | 968 ms
Code Layout: 258 ms | 190 ms
Commit Output File: 6 ms | 7 ms
PDB Emission (Cumulative): 6691 ms | 4253 ms
Add Objects: 4341 ms | 2927 ms
Type Merging: 2814 ms | 1269 ms -55%!
Symbol Merging: 1509 ms | 1645 ms
Publics Stream Layout: 111 ms | 112 ms
TPI Stream Layout: 764 ms | 26 ms trivial
Commit to Disk: 1322 ms | 1036 ms -300ms
----------------------------------------- --------
Total Link Time: 8416 ms 5882 ms -30% overall
The main source of the additional overhead in the single-threaded case
is the need to iterate all .debug$T sections up front to check which
type records should go in the IPI stream. See fillIsItemIndexFromDebugT.
With changes to the .debug$H section, we could pre-calculate this info
and eliminate the need to do this walk up front. That should restore
single-threaded performance back to what it was before this change.
This change will cause LLD to be much more parallel than it used to, and
for users who do multiple links in parallel, it could regress
performance. However, when the user is only doing one link, it's a huge
improvement. In the future, we can use NT worker threads to avoid
oversaturating the machine with work, but for now, this is such an
improvement for the single-link use case that I think we should land
this as is.
Algorithm
----------
Before this change, we essentially used a
DenseMap<GloballyHashedType, TypeIndex> to check if a type has already
been seen, and if it hasn't been seen, insert it now and use the next
available type index for it in the destination type stream. DenseMap
does not support concurrent insertion, and even if it did, the linker
must be deterministic: it cannot produce different PDBs by using
different numbers of threads. The output type stream must be in the same
order regardless of the order of hash table insertions.
In order to create a hash table that supports concurrent insertion, the
table cells must be small enough that they can be updated atomically.
The algorithm I used for updating the table using linear probing is
described in this paper, "Concurrent Hash Tables: Fast and General(?)!":
https://dl.acm.org/doi/10.1145/3309206
The GHashCell in this change is essentially a pair of 32-bit integer
indices: <sourceIndex, typeIndex>. The sourceIndex is the index of the
TpiSource object, and it represents an input type stream. The typeIndex
is the index of the type in the stream. Together, we have something like
a ragged 2D array of ghashes, which can be looked up as:
tpiSources[tpiSrcIndex]->ghashes[typeIndex]
By using these side tables, we can omit the key data from the hash
table, and keep the table cell small. There is a cost to this: resolving
hash table collisions requires many more loads than simply looking at
the key in the same cache line as the insertion position. However, most
supported platforms should have a 64-bit CAS operation to update the
cell atomically.
To make the result of concurrent insertion deterministic, the cell
payloads must have a priority function. Defining one is pretty
straightforward: compare the two 32-bit numbers as a combined 64-bit
number. This means that types coming from inputs earlier on the command
line have a higher priority and are more likely to appear earlier in the
final PDB type stream than types from an input appearing later on the
link line.
After table insertion, the non-empty cells in the table can be copied
out of the main table and sorted by priority to determine the ordering
of the final type index stream. At this point, item and type records
must be separated, either by sorting or by splitting into two arrays,
and I chose sorting. This is why the GHashCell must contain the isItem
bit.
Once the final PDB TPI stream ordering is known, we need to compute a
mapping from source type index to PDB type index. To avoid starting over
from scratch and looking up every type again by its ghash, we save the
insertion position of every hash table insertion during the first
insertion phase. Because the table does not support rehashing, the
insertion position is stable. Using the array of insertion positions
indexed by source type index, we can replace the source type indices in
the ghash table cells with the PDB type indices.
Once the table cells have been updated to contain PDB type indices, the
mapping for each type source can be computed in parallel. Simply iterate
the list of cell positions and replace them with the PDB type index,
since the insertion positions are no longer needed.
Once we have a source to destination type index mapping for every type
source, there are no more data dependencies. We know which type records
are "unique" (not duplicates), and what their final type indices will
be. We can do the remapping in parallel, and accumulate type sizes and
type hashes in parallel by type source.
Lastly, TPI stream layout must be done serially. Accumulate all the type
records, sizes, and hashes, and add them to the PDB.
Differential Revision: https://reviews.llvm.org/D87805
This makes type merging much faster (-24% on chrome.dll) when multiple
threads are available, but it slightly increases the time to link (+10%)
when /threads:1 is passed. With only one more thread, the new type
merging is faster (-11%). The output PDB should be identical to what it
was before this change.
To give an idea, here is the /time output placed side by side:
BEFORE | AFTER
Input File Reading: 956 ms | 968 ms
Code Layout: 258 ms | 190 ms
Commit Output File: 6 ms | 7 ms
PDB Emission (Cumulative): 6691 ms | 4253 ms
Add Objects: 4341 ms | 2927 ms
Type Merging: 2814 ms | 1269 ms -55%!
Symbol Merging: 1509 ms | 1645 ms
Publics Stream Layout: 111 ms | 112 ms
TPI Stream Layout: 764 ms | 26 ms trivial
Commit to Disk: 1322 ms | 1036 ms -300ms
----------------------------------------- --------
Total Link Time: 8416 ms 5882 ms -30% overall
The main source of the additional overhead in the single-threaded case
is the need to iterate all .debug$T sections up front to check which
type records should go in the IPI stream. See fillIsItemIndexFromDebugT.
With changes to the .debug$H section, we could pre-calculate this info
and eliminate the need to do this walk up front. That should restore
single-threaded performance back to what it was before this change.
This change will cause LLD to be much more parallel than it used to, and
for users who do multiple links in parallel, it could regress
performance. However, when the user is only doing one link, it's a huge
improvement. In the future, we can use NT worker threads to avoid
oversaturating the machine with work, but for now, this is such an
improvement for the single-link use case that I think we should land
this as is.
Algorithm
----------
Before this change, we essentially used a
DenseMap<GloballyHashedType, TypeIndex> to check if a type has already
been seen, and if it hasn't been seen, insert it now and use the next
available type index for it in the destination type stream. DenseMap
does not support concurrent insertion, and even if it did, the linker
must be deterministic: it cannot produce different PDBs by using
different numbers of threads. The output type stream must be in the same
order regardless of the order of hash table insertions.
In order to create a hash table that supports concurrent insertion, the
table cells must be small enough that they can be updated atomically.
The algorithm I used for updating the table using linear probing is
described in this paper, "Concurrent Hash Tables: Fast and General(?)!":
https://dl.acm.org/doi/10.1145/3309206
The GHashCell in this change is essentially a pair of 32-bit integer
indices: <sourceIndex, typeIndex>. The sourceIndex is the index of the
TpiSource object, and it represents an input type stream. The typeIndex
is the index of the type in the stream. Together, we have something like
a ragged 2D array of ghashes, which can be looked up as:
tpiSources[tpiSrcIndex]->ghashes[typeIndex]
By using these side tables, we can omit the key data from the hash
table, and keep the table cell small. There is a cost to this: resolving
hash table collisions requires many more loads than simply looking at
the key in the same cache line as the insertion position. However, most
supported platforms should have a 64-bit CAS operation to update the
cell atomically.
To make the result of concurrent insertion deterministic, the cell
payloads must have a priority function. Defining one is pretty
straightforward: compare the two 32-bit numbers as a combined 64-bit
number. This means that types coming from inputs earlier on the command
line have a higher priority and are more likely to appear earlier in the
final PDB type stream than types from an input appearing later on the
link line.
After table insertion, the non-empty cells in the table can be copied
out of the main table and sorted by priority to determine the ordering
of the final type index stream. At this point, item and type records
must be separated, either by sorting or by splitting into two arrays,
and I chose sorting. This is why the GHashCell must contain the isItem
bit.
Once the final PDB TPI stream ordering is known, we need to compute a
mapping from source type index to PDB type index. To avoid starting over
from scratch and looking up every type again by its ghash, we save the
insertion position of every hash table insertion during the first
insertion phase. Because the table does not support rehashing, the
insertion position is stable. Using the array of insertion positions
indexed by source type index, we can replace the source type indices in
the ghash table cells with the PDB type indices.
Once the table cells have been updated to contain PDB type indices, the
mapping for each type source can be computed in parallel. Simply iterate
the list of cell positions and replace them with the PDB type index,
since the insertion positions are no longer needed.
Once we have a source to destination type index mapping for every type
source, there are no more data dependencies. We know which type records
are "unique" (not duplicates), and what their final type indices will
be. We can do the remapping in parallel, and accumulate type sizes and
type hashes in parallel by type source.
Lastly, TPI stream layout must be done serially. Accumulate all the type
records, sizes, and hashes, and add them to the PDB.
Differential Revision: https://reviews.llvm.org/D87805
Extending the lifetime of these type index mappings does increase memory
usage (+2% in my case), but it decouples type merging from symbol
merging. This is a pre-requisite for two changes that I have in mind:
- parallel type merging: speeds up slow type merging
- defered symbol merging: avoid heap allocating (relocating) all symbols
This eliminates CVIndexMap and moves its data into TpiSource. The maps
are also split into a SmallVector and ArrayRef component, so that the
ipiMap can alias the tpiMap for /Z7 object files, and so that both maps
can simply alias the PDB type server maps for /Zi files.
Splitting TypeServerSource establishes that all input types to be merged
can be identified with two 32-bit indices:
- The index of the TpiSource object
- The type index of the record
This is useful, because this information can be stored in a single
64-bit atomic word to enable concurrent hashtable insertion.
One last change is that now all object files with debugChunks get a
TpiSource, even if they have no type info. This avoids some null checks
and special cases.
Differential Revision: https://reviews.llvm.org/D87736